Aili Chen
Ph.D Student
Fudan University
Biography
Hi, I'm Aili Chen (陈艾利). I am a first-year Ph.D. student at Fudan University, advised by Prof. Yanghua Xiao at Knowledge Work Lab. Previously, I received my Bachelor's degree from Fudan University in 2024. I have interest in Large Language Model, especially in reasoning models and autonomous agents:
- Reasoning & Planning
- Language Agent
- LLM Personalization
- Music, Photography, and Travel
-
Ph.D. in CS, 2024 - 2029 (expected)
Fudan University
-
B.S. in Information Security, 2020 - 2024
Fudan University
News
-
July. 2025: 🇦🇹 Attending ACL 2025@Vienna! I will present DEEPER! Looking forward to meeting everyone!
-
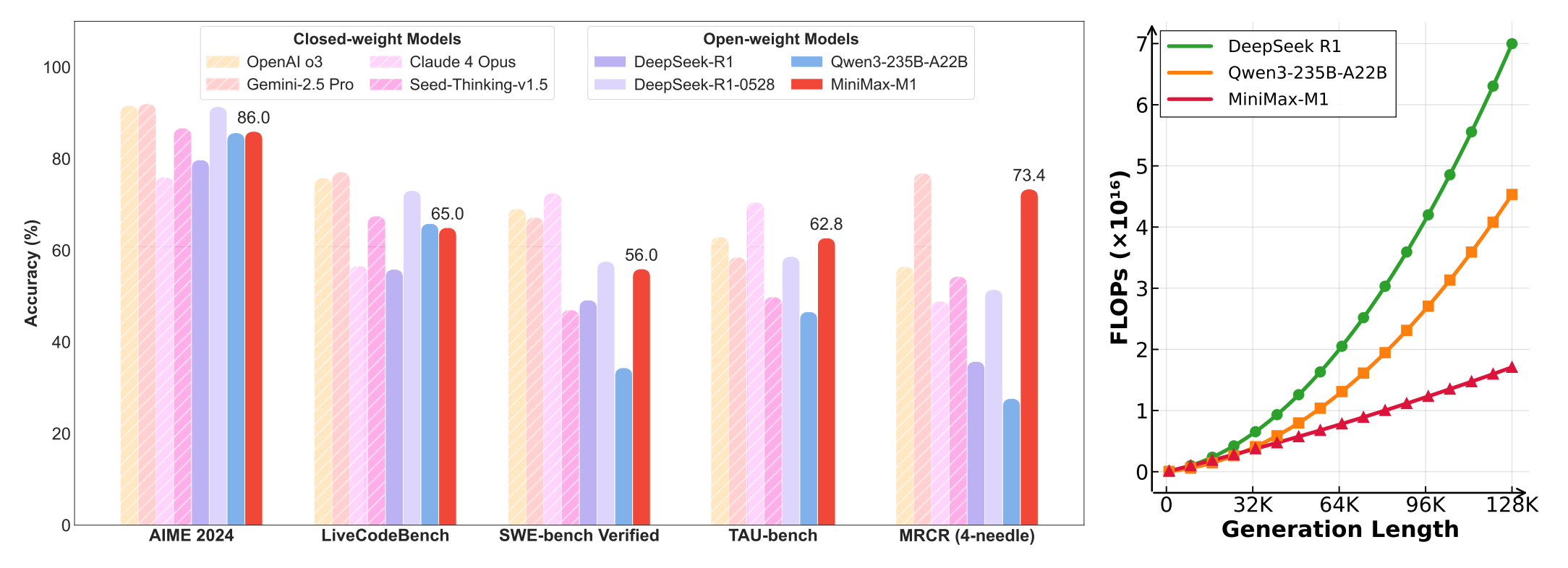
Jun. 2025: 🔔 Introducing Minimax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism!
-
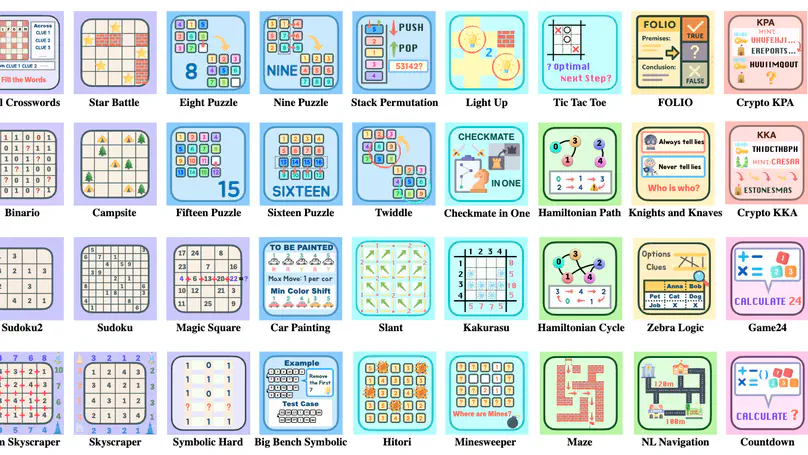
May. 2025: 🔔 Check out Enigmata! A complete pipeline for advancing logical reasoning in LLMs, from data generation → verification → RLVR training → evaluation.
-
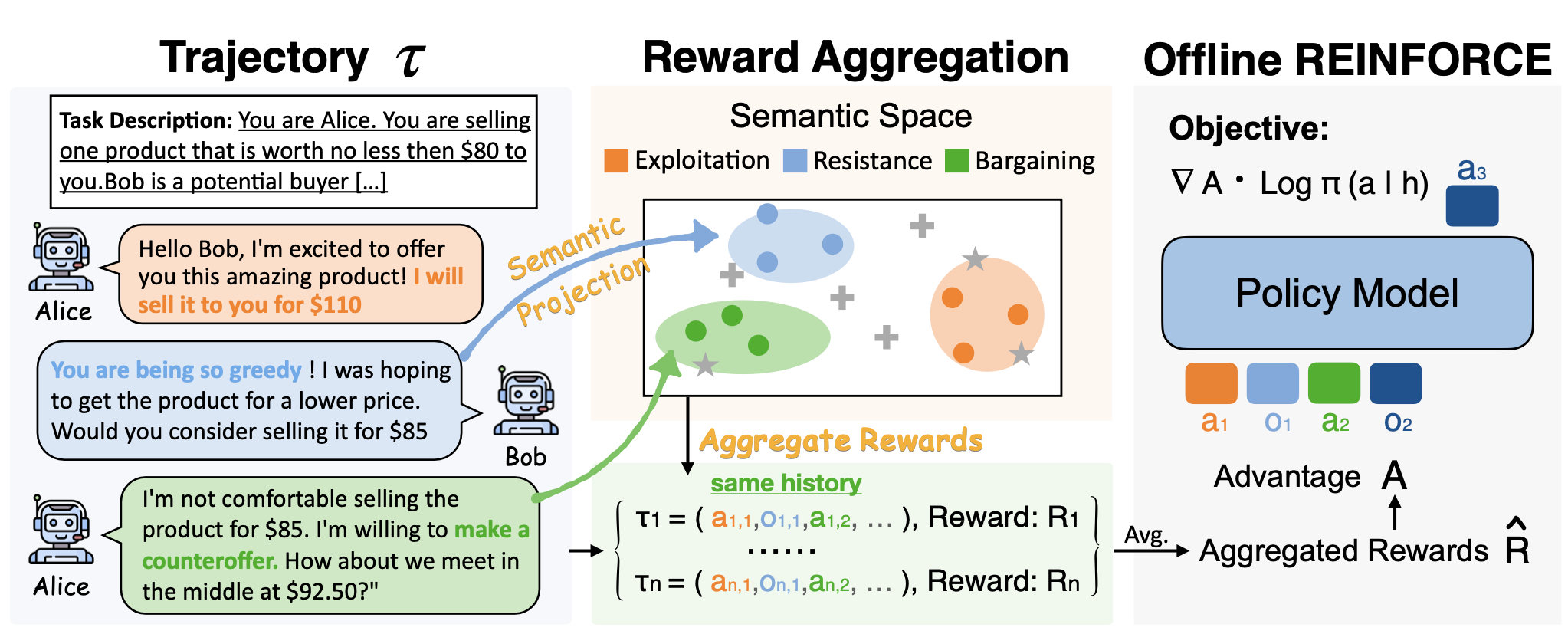
May. 2025: 🔔 Check out ARIA! we propose ARIA, a method that Aggregates Rewards in Intention space to enable efficient and effective language Agents training.
-
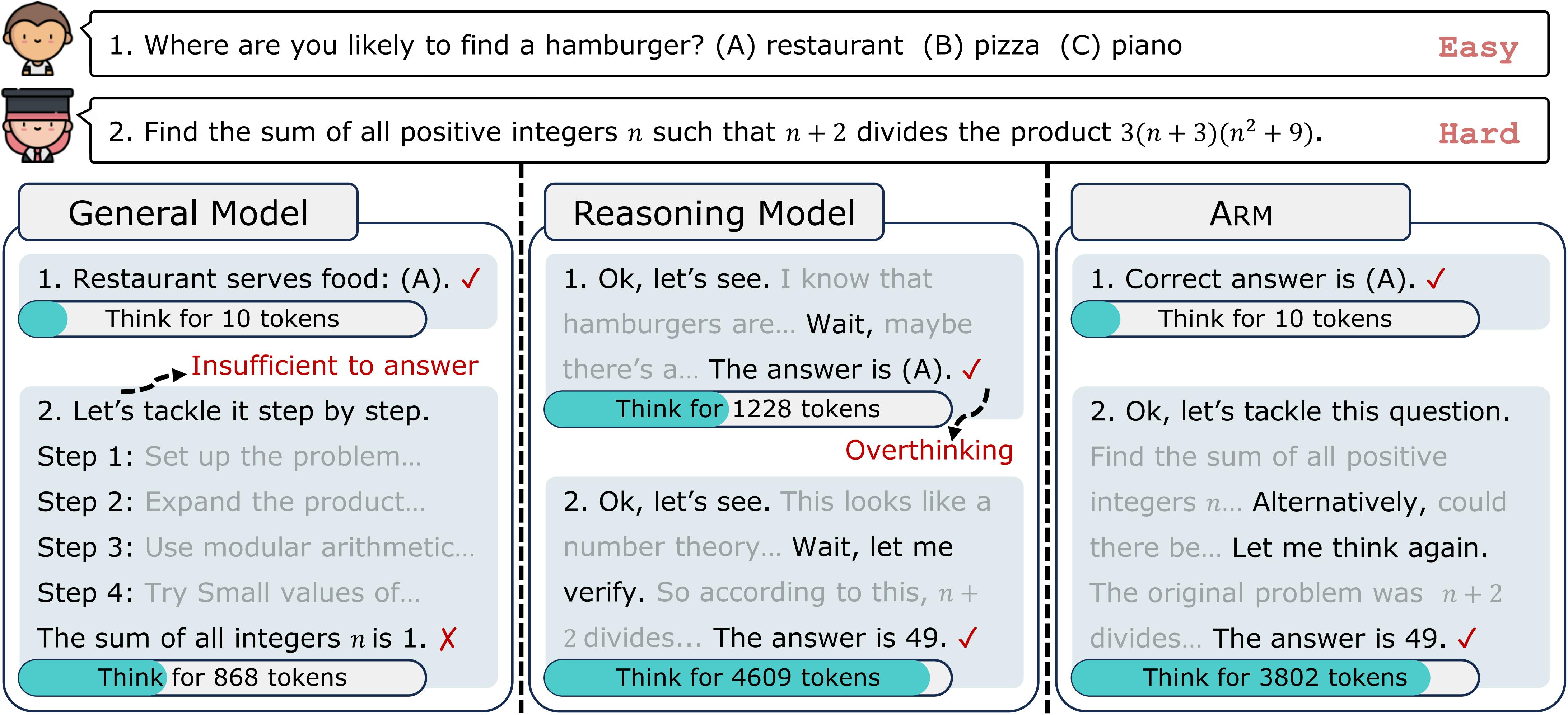
May. 2025: 🔔 Check out ARM! LLMs often suffer from "overthinking" - excessive reasoning that wastes computational resources. ARM introduces adaptive reasoning formats and multiple modes to optimize token usage while maintaining performance.
-
May. 2025: 🔔 Check out SynLogic! A comprehensive logical reasoning data synthesis framework that generates diverse, verifiable reasoning data at scale for learning logical reasoning and beyond.
-
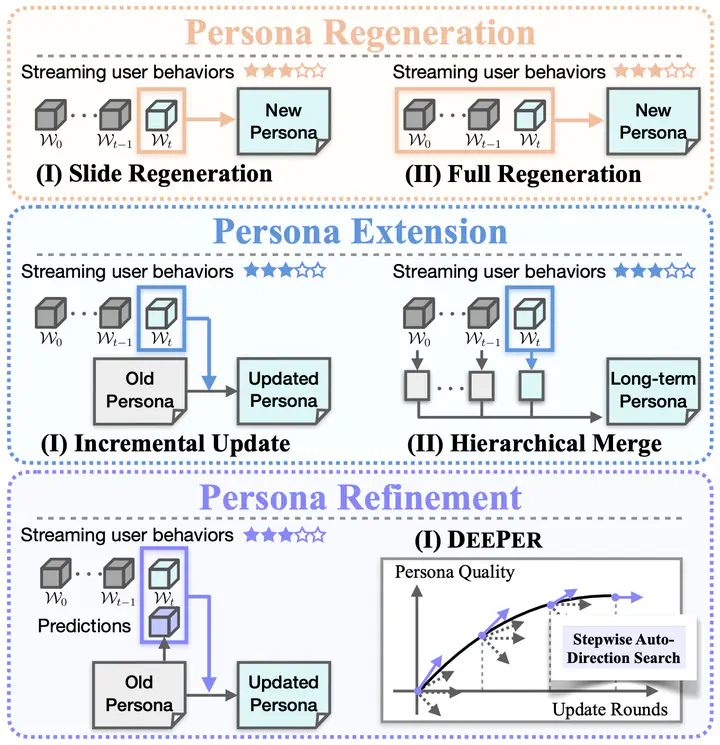
May. 2025: 🎉 Our paper DEEPER is accepted to ACL 2025!
-
Mar. 2025: 🎉 Our paper SelfGoal is accepted to NAACL 2025!
-
Jan. 2025: 🎉 Our paper Think Thrice Before You Act is accepted to ICLR 2025!
-
Sep. 2024: 🎉 Our survey paper on role-playing agents is accepted to TMLR!
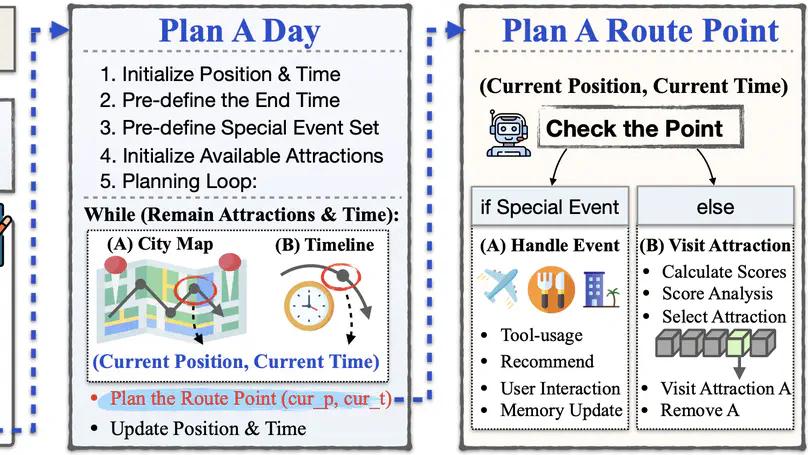
Aug. 2024: 🔔 Check out TravelAgent! We introduce an LLM-powered travel planning system that generates rational comprehensive and personalized itineraries.